
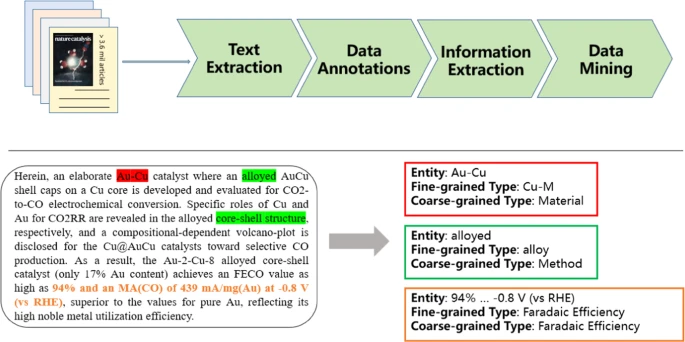
A corpus of CO2 electrocatalytic reduction process extracted from the scientific literature
A corpus of CO2 electrocatalytic reduction processb extracted from the scientific literature
The electrocatalytic CO2 reduction process has gained enormous attention for both environmental protection and chemicals production. Thereinto, the design of new electrocatalysts with high activity and selectivity can draw inspiration from the abundant scientific literature. An annotated and verified corpus made from massive literature can assist the development of natural language processing (NLP) models, which can offer insight to help guide the understanding of these underlying mechanisms. To facilitate data mining in this direction, we present a benchmark corpus of 6,086 records manually extracted from 835 electrocatalytic publications, along with an extended corpus with 145,179 records in this article. In this corpus, nine types of knowledge such as material, regulation method, product, faradaic efficiency, cell setup, electrolyte, synthesis method, current density, and voltage are provided by either annotating or extracting. Machine learning algorithms can be applied to the corpus to help scientists find new and effective electrocatalysts. Furthermore, researchers familiar with NLP can use this corpus to design domain-specific named entity recognition (NER) models.
I believe that is one of the most important information for me. And i’m satisfied reading your article. However wanna commentary on some common issues, The web site style is wonderful, the articles is in point of fact great : D. Good process, cheers
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post…
Wow, fantastic blog layout! How long have you ever been running a blog for?
you make blogging glance easy. The whole glance of your site is great, let alone the content!
You can see similar here sklep